
Lessons of Enterprise Scale Analytics, Part 4
In our last entry in this Lessons series, we explored where visualization fits within the larger context of Analytics and Business Intelligence. This month I’d like to get a little bit more abstract, and talk about how important it is to cultivate a deep understanding of the data models that drive and inform our Analytics.
While working as a Success Specialist at Salesforce, I advised a large number of clients, but generally didn’t get the chance to work with them long enough to really get to know their business or how they use their data. In the past three years as a boutique consulting firm, having the space to both consider our clients’ data model at a slow, deliberate pace as well as see it in action when applied to business processes has turned out to be one of my favorite aspects of the job. Admins and leadership teams make data structure decisions every day, and it’s part of our work as analysts to understand how those decisions affect things like KPI logic (especially aggregations), historical trending, and the ability to build predictive models.
What is a data model?
Central to every modern data storage solution is the idea of a data model. For the purposes of this discussion, a data model is a generalization we make based on how our metadata aligns with our business processes. Data models can be as simple as a single table that represents the focus of your business. (We’ve actually seen these in real life - national and international firms that manage big revenue streams through one Salesforce object.) They can also be extremely complicated. Figure 1 below gives a sense of what “complicated” starts to look like on a practical level. Note the multiple junction objects, the hierarchical relationships, and the mixture of standard and custom objects. Each of these features represents an aspect of how we actually use data for our business, such as the fact that one Interaction or Activity could easily relate to multiple parent objects like Opportunities or Relationships while also including any number of internal and external attendees.
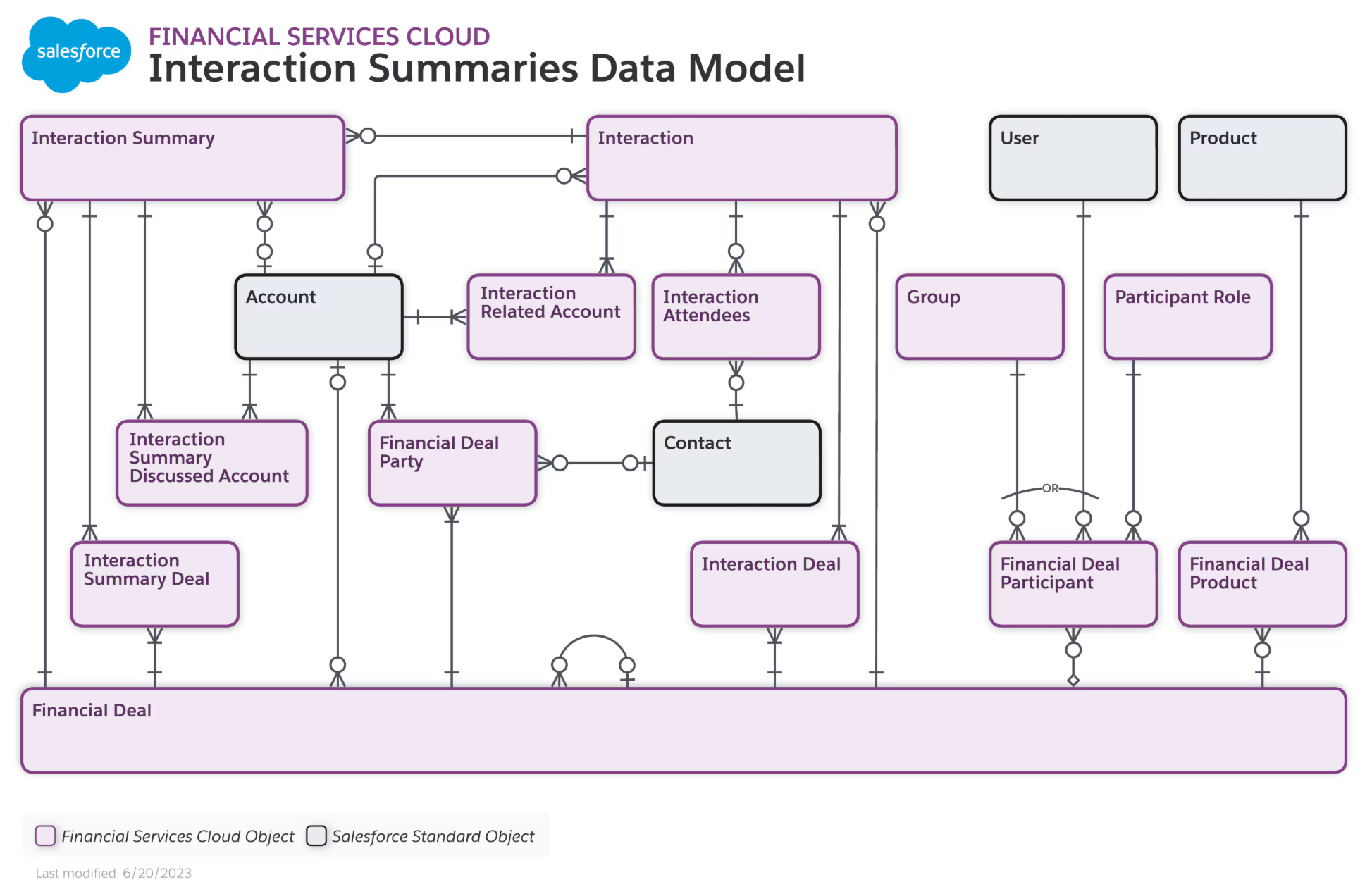
Fig 1: A representation of a data model for Interactions in Financial Services Cloud
At a small scale, the first step is understanding relationships like one-to-one, one-to-many and many-to-many, and where they apply to our business entities. As an example, consider an independent physical therapist who sees clients by appointment. In their data model, each therapy session might be associated with only a single appointment record, so those entities have a one-to-one relationship. In contrast, each client could potentially receive multiple services per session, and each of those services could be offered to multiple clients, so those entities have a many-to-many relationship. The challenge is that while the language of data models is small and pretty easy to grasp, the actual application of these relationships can take on countless forms. Therefore as analysts, developers, and consultants, it’s imperative that we get as familiar with our clients’ data models as we can.
You have to understand the data model intuitively.
A huge part of what we do as Analytics builders is creating Datasets. The power of CRM Analytics (and many similar Business Intelligence tools) comes from taking Salesforce CRM data which is optimized as a traditional relational database for long term storage and retrieval, and changing the structure to optimize the data for dynamic dashboard queries. This gives us as developers plenty of freedom, including the freedom to build incorrect structures that lose data or inadvertently change the data grain. It’s important to note that the impact of getting something wrong isn’t necessarily linear: incorrect or sub-optimal implementations are significantly more expensive at scale than they are for newer or smaller builds. We avoid these pitfalls and build robust Datasets by getting to know our data model not only at the level of grains and join keys, but also at the level of the day-to-day operations where our end users apply the insights we provide.
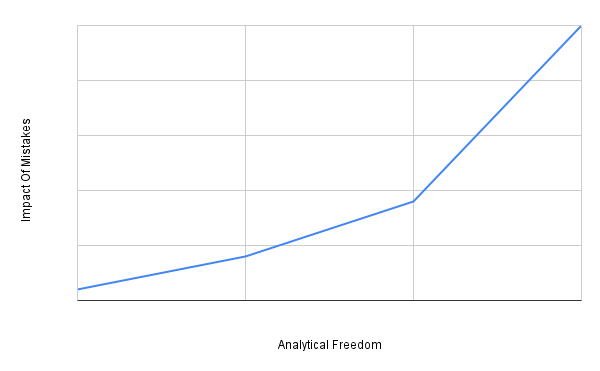
Fig 2: Analytics tools give us freedom at the cost of greater risk of high-impact mistakes.
For example, in the standard Salesforce model, we have many Opportunities to one Account, and therefore the lookup, (aka foreign key or join key), between those objects lives on the Opportunity record. The CRMA Recipe builder allows us to create a lookup join with the Account on the left side and Opportunity on the right, using the Account Id as a key. A build like this might initially look correct, and it would cause no errors, but as we start to explore the data we’ll notice that we’ve joined in only one Opportunity per Account, and there’s no guarantee that it will be the same Opportunity from Recipe run to Recipe run.Therefore, we have to know our data model well enough to know where the lookup fields live and what kind of business relationship exists between the objects, so that our Datasets include all appropriate data and represent a consistent level of detail. In practice this entails regular conversations with our business users to get a sense of how the data’s being used day-to-day and how the database structure reflects those business relationships. We want our Analytics Dataset structure to both preserve and enrich that database structure as much as possible.

Fig 3a: We can build a join like this that looks correct at first glance
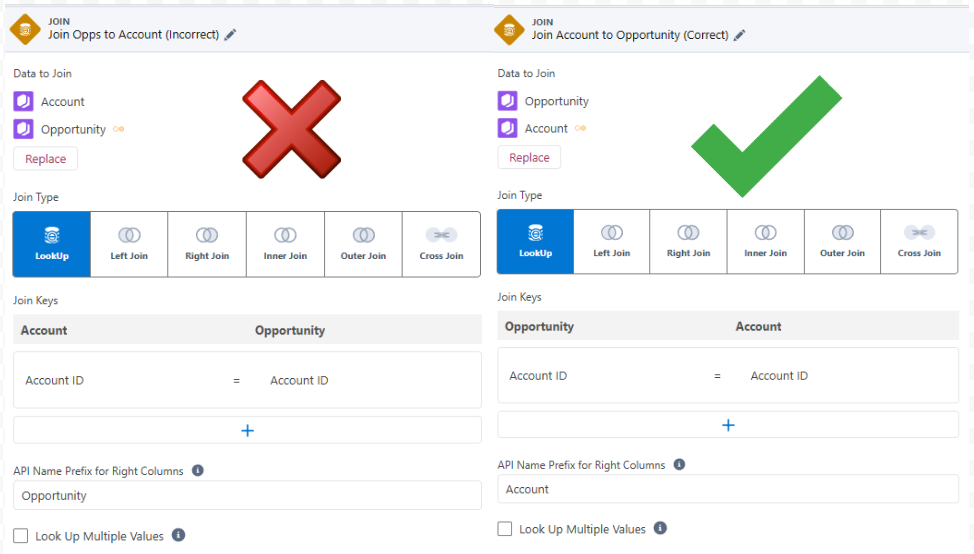
Fig 3b: However, the configuration on the left is non-deterministic. We don’t know which Opportunity will match here.
This part of the Enterprise Analytics toolset only comes with practice and technical understanding. Sometimes the relationship between the data model and the business processes is very clear. Other times we might have multiple junction objects between standard and custom objects, each of which represent a different department’s approach to similar goals. It’s our job as experts to know the right questions to ask to identify the key details that differentiate those objects and know where and how to add them to our analyses.Over time, this comfortable understanding of the subtleties and nuances of of a specific CRM implementation can even empower us as analysts to give strategic advice back to the admin and leadership teams, creating a virtuous cycle of productivity centered around the data model.
In our upcoming final installment of the Lessons of Enterprise Analytics series, we’ll talk about the often hidden and undervalued power of heavy-duty processing in the data layer. It ain’t always glamorous, but it can be the key factor in Analytics scalability.